Infoblox DNS Security Resource Center
DNS Security Extensions (DNSSEC) are the suite of IETF specifications for securing DNS (DNS Security). DNS is one of the oldest and most relied-on protocols of the modern Internet and is utilized by almost all other Internet services and protocols. This makes DNS an appealing target to attackers. Unfortunately, the original design of the Domain Name System (DNS) did not include security considerations. DNSSEC addresses this oversight by adding DNS security protocols that enhance security while maintaining backward compatibility. The process of securing DNS can be complicated. Consequently, Infoblox has created this resource center as a tool to explain the basics of DNSSEC, DNS security more broadly, and to provide additional resources for further learning and application. The center includes a DNS security overview, as well as sections on DNS security issues & threats, DNSSEC solutions, best practices, DNS client security, and frequently asked questions.
Welcome to the Infoblox DNS Security Resource Center!
1. DNS Security Overview
The Domain Name System (DNS) is ubiquitous, underpinning virtually every interaction on the Internet. As one of the oldest and most relied-on protocols of the modern Internet, DNS is utilized by almost all other services and protocols, making DNS a highly appealing target to attackers. Additionally, because it is one of the most relied-on protocols, stopping attacks that use DNS as a vector can be extremely difficult to stop.
How DNS Attacks Work
In DNS attacks, the two primary attack types are Authoritative attacks and Caching Recursive attacks. Authoritative attacks include DDoS attacks, Amplification attacks (link), or Reflection attacks (link), to name a few. Caching Recursive attacks, such as Cache Poisoning attacks, or DNS Hijacking attacks all target DNS vulnerabilities as well. Just like wine, there are also a few outliers, such as DNS Tunneling attacks (link). However, most DNS attacks are either Authoritative or Caching Recursive.
The process of securing DNS is complicated because, unlike most other protocols, the principal purpose of DNS is to both publish information as well as allow clients to access that information. So, the methods we use to defend DNS often have to stay away from the classic, simple blocking techniques.
We often get asked, “What is DNS Security and how does it work?” In this section of the site, we try to answer just that. The tools at our disposal to protect DNS include but are not limited to signature recognition (link), Response Rate Limiting(RRL) (link) and Response Policy Zones(RPZ) (link). First, let’s briefly review the history of DNS and what it includes.
1.1 DNS History
DNS stands for Domain Name System and is an Internet protocol that converts human-readable names to IP addresses, changes IP addresses back to names, and provides easy-to-remember names for many Internet-based services, such as e-mail.
At the dawning of the Internet, or as it was known back then, the ARPANET (Advanced Research Projects Agency Network), very few people and machines were online. Each computer using the Internet had an IP address, but since there were so few IP addresses, memorizing them was not a big deal.
As the number of machines quickly grew, people thought it would be a good idea to use more human-friendly names. Instead of remembering a computer’s IP address, such as 128.171.32.45, ARPANET users could enter names such as GOPHER-HAWAII. A single text file named HOSTS.TXT served as a name-to-address map. The Stanford Research Institute (then a part of ARPANET) manually maintained the file, also known as the hosts file, in a single place, and distributed it to ARPANET users.
This centralized system quickly proved unscalable. Computer scientist and Internet pioneer Paul Mockapetris began work writing a standards document to define a replacement for host files. He took his proposed standard to the Internet Engineering Task Force (IETF), which still today produces standards documents that define how Internet protocols should operate and interoperate.
In 1983, Mockapetris published the first standards document in the IETF related to DNS. This document would become the basis for the DNS. His proposal called for a decentralized, distributed structure of name servers. More than 30 years later, this same system is still very much in use, making Paul Mockapetris the official Father of DNS.

Figure 1-1: DNS is a decentralized, distributed structure of name servers that has enabled the Internet to scale.
1.2 DNS Structure
The DNS system is structured to distribute responsibility for an ever-growing list of network device names. It does this by creating a hierarchy of responsibility. This hierarchy is often represented by an upside-down tree, such as Figure 1-1, where the root servers are at the top, and the leaves (which represent all the end host nodes on the Internet) are at the bottom. The entire tree represents the namespace of DNS. Each server that is responsible for part of the namespace is called a “name server.” Some name servers send packets along until they reach an answer.
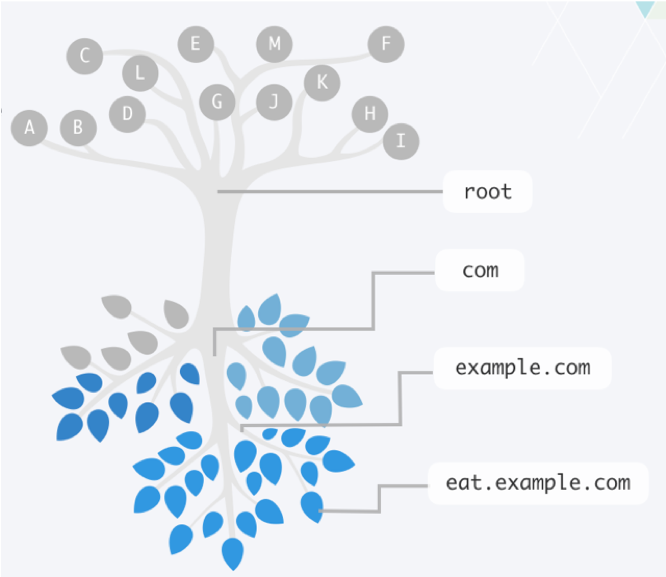 Figure 1-2: Like the branches of a tree, each domain name can have multiple subdomains.
Figure 1-2: Like the branches of a tree, each domain name can have multiple subdomains.1.3 Authority and Zones
A DNS zone is a domain that a party is responsible for maintaining, minus any subdomains the party delegated control of to another party. The responsible party uses that zone to maintain the resource records for that domain. Resource records map information to common names. The server where the party edits the resource records is typically called the primary name server or master name server. Because a single server isn’t enough for a robust solution, additional name servers can also be authoritative for a zone by getting a copy of the zone data from the primary or master name server through a process called a zone transfer. These additional servers are called secondary name servers or slave name servers (an unfortunate, antiquated term).
1.4 Resource Records and common uses
Resource records identify the information or services associated with a given domain name.
All resource records use the same format, which we discuss in the following list:
- Name: A domain name in which this resource record pertains.
- TTL: A 32-bit integer that specifies the time interval that the resource record may be cached before it should be discarded.
- Class: Two octets which specify the class of the data in the RDATA field. The most common type is IN for Internet.
- Type: This field specifies the meaning of the data in the RDATA field.
- RDLENGTH: A 16-bit integer that specifies the length in octets of the RDATA text, for instance, how large is the payload.
- RDATA: A variable-length string that describes the resource. The format varies according to the TYPE and CLASS of the resource record.
Although all resource records share a common overall structure, they may contain different types of information in their RDATA field, such as network- or service-specific information.
Click through to learn more about resource records and their common uses.
1.5 Query Path, Recursion, and Iteration
Query path and Recursion
A query path is the set of queries starting from the initial question from the client and finishing with the answer the client receives. A query path can be as simple as a client asking a server and receiving an answer directly. However, a query path can also be complex and include multiple servers working together to track down the answer. Understanding the query path of a given question allows you to troubleshoot issues and identify where you need to focus your DNS security.
It’s important to understand what we mean when we say a client asks a question. When a DNS client asks simple questions like “What is the IPv4 address of www.google.com?” a stub resolver is the piece of software code that sends the DNS question. For the scope of this book , we can assume that a “client” is an application or a machine that has a stub resolver running on it. Therefore, a web browser is a client, and a laptop or mobile phone can also be a client.
When a client asks a question, it is unable to follow referrals given by other name servers to track down the answer on its own. It has to rely on a full-fledged DNS server, which may call on other name servers, to chase down the answer. This name server acting on behalf of the client is called recursion.
Figure 1-3 illustrates several name servers involved in answering a simple question.
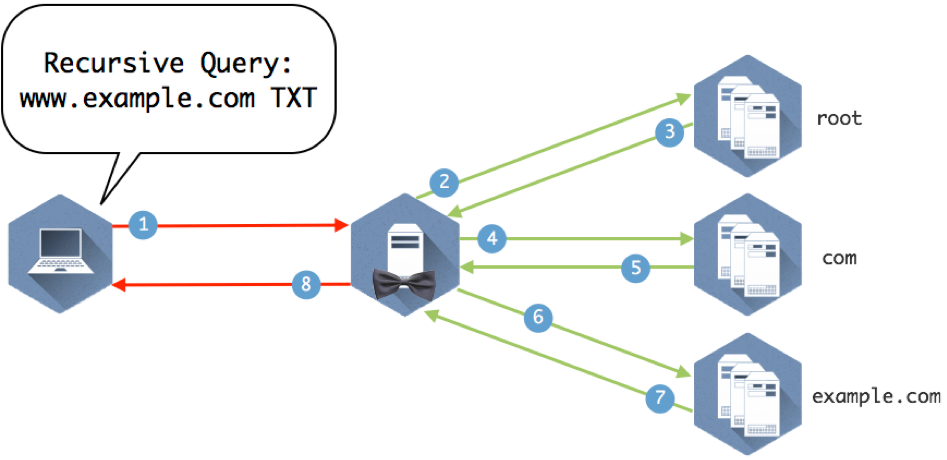
Figure 1-3: Eight queries and answers make up the query path required to get this client the answer to “What is the IP address of www.example.com”
Now we can take a look at the different parts of the query path in Figure 1-1 and break down how the servers use recursion and iteration to move down the DNS tree and find the answer the client is looking for.
Recursion is the process of repeatedly asking the question to name servers and following referrals until finding the name server with the answer. The recursive query says, “I would like to know the answer to this question. Moreover, if you don’t know the answer, please ask others until you’ve found the answer.” It is this behavior of asking on behalf of the end client that is considered recursion.
Iteration
An iterative name query is typically sent by DNS servers to other DNS servers, in pursuit of finding the answer. A critical difference between iteration and recursion is that iterative queries must have the ability to follow referrals, i.e., track down the answer.
Figure 1-4 provides the details to the query path to illustrate how it all comes together.
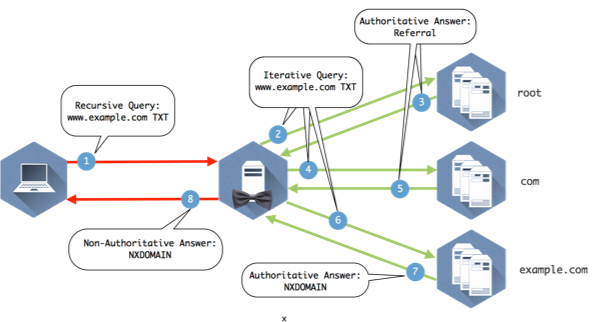
Figure 1-4: Explanation below
- The client queries the recursive name server that it is configured to use.
- The recursive server checks its internal cache. If it doesn’t find the answer to the question, it checks its root hints file and sends the query to one of the 13 root name servers listed in the file.
- The root name server does not contain specific records that answer the question, but it does know where the com name servers. It sends a referral in the form of the NS RRSET for the com name servers and the A records for those name servers. These matching A records are called glue records.
- The recursive server caches the responses from the root name server and queries one of the com servers it was given for www.example.com
- The com name servers do not contain www.example.com, but someone has registered example.com and provided com with the information for their name servers. The com name server sends a referral of the NS and A records for example.com
- The recursive server caches the records from com and queries one of the example.com name servers provided in the referral.
- The example.com name server returns the answer from the authoritative zone example.com
- The recursive name server caches the answer returned from the example.com name servers and sends the response to the client.
2. DNS Security Issues & Threats
2.1 DDoS Attacks
There are many types of distributed denial of service (DDoS) attacks. When it comes to DNS, we can look at specific types of attacks that are used to overwhelm DNS servers, thus rendering the DNS service unavailable. When an attack on the DNS is successful, it can bring an organization to a screeching halt.
The two main DDoS attack methodologies we want to look at are amplification and reflection. While technically two different attack tactics, attackers often combine amplification and reflection attacks.
Amplification DDoS Attacks
An amplification attack is a technique where a small query can trigger a large response, such as querying for a TXT record or a zone transfer when you haven’t secured zone transfers to only your trusted sources. By flooding the server with short requests that require long responses, even a relatively weak computer can overload a DNS server. The DNS server is so busy doing the heavy lifting to respond to all these bogus requests that it doesn’t have time to respond to legitimate ones.
Reflection DDoS Attacks
A reflection attack sends queries that look like they came from the victim of the attack. The response (often a large, amplified answer) is sent to the victim, who never asked, and the amount of the response traffic could potentially overwhelm the victim’s network.
In a reflection attack, an attacker sends a query to a recursive name server with a spoofed source IP address. Instead of his real IP address, he places the target (victim) IP address as the source IP address. The recursive name server does the legwork, retrieves the answer to the query from the authoritative name server, and sends the answer to the unsuspecting victim.
Combination DDoS Attacks
Now the attacker combines the two techniques by spoofing the victim’s IP address and sending a carefully crafted query that will result in a large payload. This is a very effective DDoS attack; the authoritative name server provides the amplification, and the recursive name server provides the reflection. This allows the attacker to attack two different victims at the same time. It also causes the victim of the amplification attack to possibly believe they were attacked by the second victim, causing potentially even more mayhem.
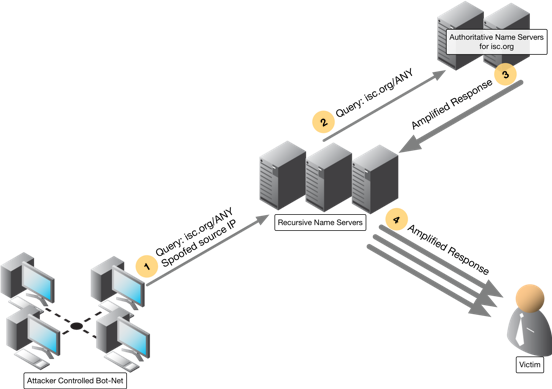
Figure 1-5: An amplified reflection attack.
2.2 Cache Poisoning
Cache poisoning, a form of DNS spoofing focuses on corrupting the cached answers on the recursive name servers, either through software exploits or protocol weaknesses. Software exploits differ from vendor to vendor and can be patched with software updates. Major protocol weakneses that cannot be easily fixed with software updates include:
DNS Weakness 1: UDP
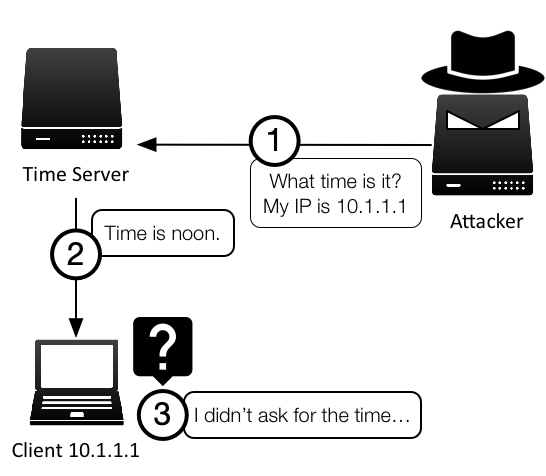
Being a mostly UDP-based protocol has its advantages: UDP (User Datagram Protocol) is a lightweight protocol in comparison to TCP, tends to run faster, and is less resource intensive. However, UDP is much easier to spoof than TCP, meaning an attacker can craft a UDP packet with any source IP address easily. Figure 1-1 illustrates this type of source IP address spoofing that is easily accomplished with UDP. This type of source IP spoofing is also known as “reflection,” is discussed in more detail here.
Figure 1-6: UDP Reflection
DNS Weakness 2: (Lack of) Randomness
When a recursive name server makes a query, it sets the value of five (5) fields. If the response to the query matches the values of the five fields, it accepts the answer as legitimate. It then returns it to the client and stores it in its cache.
As it turns out, four of the fields are easy to figure out and spoof, so only one field is actually meaningful: the Query ID (also known as the TXID). By most computing standards, the Query ID has relatively few possible values. It is a 16-bit number or a value between 0 and 65,535. This makes it possible for an attacker to initiate an information request on a recursive name server, then immediately spoof the responses, in order to continue to try firing a lot of responses with different Query IDs.
2.3 DNS Data Exfiltration
DNS Data Exfiltration Leverages DNS Tunneling
DNS Data Exfiltration is one of the uses of DNS Tunneling. Although there are many DNS Tunneling implementations, they all rely on the ability of clients to perform DNS queries.
How DNS Data Exfiltration Works
DNS Data Exfiltration is like stealing someone’s car without opening the garage door: You have to break the car down into small chunks that fit through the doors and windows, and then rebuild the car outside. Except in the case of data exfiltration, the malware breaks down files, sometimes even encrypting each chunk, before sneaking them off your premises to reassemble.
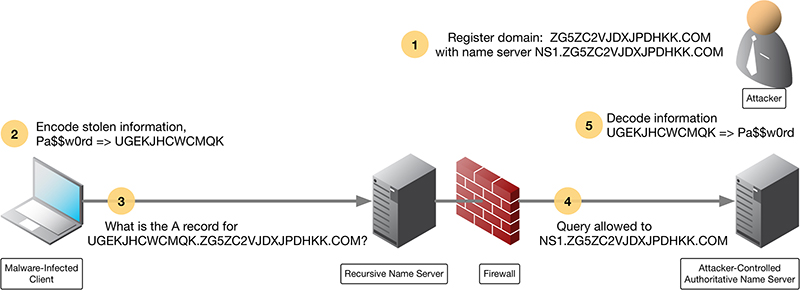
Figure 1-7 illustrates a simplified flow of how data exfiltration works over DNS:
- The attacker registers the domain name ZG5ZC2VJDXJPDHKK.COM, and sets up name server NS1.ZG5ZC2VJDXJPDHKK.COM
- The infected client encodes stolen information, in this case, the text “Pa$$w0rd”, into “UGEKJHCWCMQK”
- The client makes the DNS query for the domain with the encoded password as a subdomain: UGEKJHCWCMQK.ZG5ZC2VJDXJPDHKK.COM
- A recursive name server finds the authoritative name server NS1.ZG5ZC2VJDXJPDHKK.COM and sends the query there.
- The attacker recognizes the subdomain value as the encoded password. The attacker decodes the information UGEKJHCWCMQK back to recover “Pa$$w0rd”
In this example, it is not necessary for the client to receive a response from the malicious server, because the goal was to send information out. However, the process can easily include the malicious server sending back an exploit to be executed on the infected client.
2.4 DNS and Malware
Just like many other protocols themselves, malware leverages DNS in many ways. From infected hosts identifying command and control points, to DNS Hijacking, to identifying targets in the first phases, malware attempts to exploit the DNS protocol. Malware leverages DNS because it is a trusted protocol used to publish information that is critical to a networking client.
Two specific examples at opposite ends of the Malware and DNS security story are DNS Hijacking and the ransomware, “WannaCry.”
How DNS Hijacking Threatens DNS Security
In DNS Hijacking, malware is used to create DNS Spoofing by changing the client’s configured DNS servers, allowing the malicious party to both see what the client is querying and to misdirect the client as desired. This form of DNS Spoofing can dramatically affect the clients behavior and allow reconnaissance of the host and its behavior. A well-known malware variant is DNSChanger, a DNS hijacking trojan. Most often, this trojan is an extremely small file (+/- 1.5 kilobytes) that is designed to change the ‘NameServer’ Registry key value to a custom IP address or link.
“WannaCry” Exploits DNS
WannaCry ransomware, shown in Figure 1-1, launched on May 12, 2017. It leveraged a known and patched vulnerability in Microsoft Server Message Block (SMB) to encrypt files on users’ machines and demand ransoms of up to $600 in Bitcoin to return the files. (https://www.infoblox.com/threat-center/). In the example of WannaCry it was actually the kill switch that was tied to DNS. The Ransomware checked if a specific domain name was registered in order to be turned on and off. It actually took the good guys a while to even notice it because DNS is so ever prevalent. But once it was discovered, just by registering the domain, they were able to kill the attack.
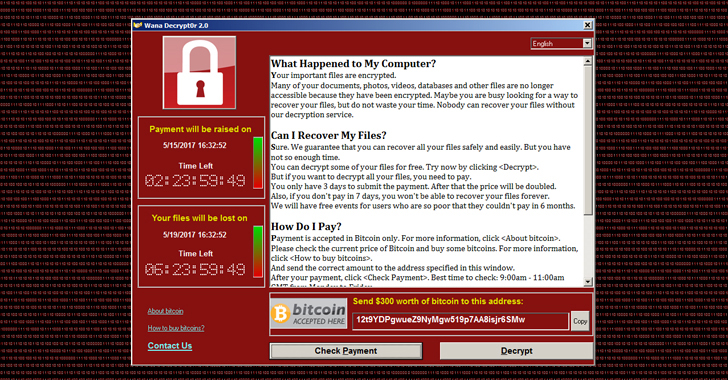
Figure 1-8: Shows the WannaCry page that was seen once a client was infected.
3. DNS Security Solutions
3.1 Response Rate Limiting (RRL)
Response Rate Limiting – Overview
Another cyberattack technique that can be even more damaging than a DDoS hack is a reflection attack, where a number of authoritative servers – these are the primary servers for a DNS zone, storing the definitive versions of all records in that zone – are used to attack a single entity.
Authoritative name servers are designed to provide answers in response to questions asked about names in a zone. So, in a reflection attack, the attacker can leverage many authoritative servers and pick servers that have far more capacity than the target itself. The sheer volume of traffic that results can quickly overwhelm routers, firewalls or other perimeter defense tools, with the result that the target is brought down.
When you look at addressing DDoS attacks against DNS infrastructure, the critical issue becomes separating valid queries from malicious queries. With DNS, we can’t simply block all the packets; we need to sort the good form the bad. Attackers are very good at making their queries look legitimate, so the trick is to look at the pattern, rate and signature of queries more than at the queries themselves. This is the fundamental concept behind response rate limiting (RRL).
Learn more about Response Rate Limiting (RRL)
3.2 DNS Security Extensions (DNSSEC)
The lack of security in DNS has been a well-known issue for decades, and one that the DNS community has been trying to solve since the late 1990s. These efforts resulted in the birth of the DNS Security Extensions (DNSSEC).
DNSSEC basics
- DNSSEC provides answer validation through public key cryptography. Public key cryptographs use of a pair of keys, one being public and one being private, that allows a DNS server to validate that the answer to a query came from the sender it says it did (in other words, that the sender wasn’t spoofed) and that the message content wasn’t changed during transmission. Keys are used to “sign” zones, meaning to create a cryptographic representation of the data that can only be turned back with the other key. This process provides both message authentication and message integrity.
- DNSSEC is backward compatible: DNSSEC can be deployed side-by-side with traditional DNS. If a domain is not yet DNSSEC-enabled, a DNSSEC-aware name server falls back to using traditional DNS.
- DNSSEC doesn’t encrypt traffic: Although DNSSEC uses both public and private keys, they’re only used for authentication purposes. Someone eavesdropping on the wire can still see all the DNS messages in plaintext; it just becomes nearly impossible to spoof.
DNSSEC requires deployment on both recursive name servers and authoritative name servers: The recursive name servers ask for additional security information and perform validation checks, while authoritative name servers provide signed resource records in responses. Figure 3-3 shows a simplified explanation of a DNSSEC-aware recursive name server, also known as a validating resolver, checking the answer it received.
Learn more about DNS Security Extensions (DNSSEC)
3.3 Response Policy Zones
Response policy zones (RPZs) are a way for you to control what your queriers can and can’t look up using a recursive DNS server. By understanding the reputation of the servers and services that clients are querying, you can determine actions to take when the recursive server receives queries for certain domain names or sees information in the DNS responses that point to those malicious servers.
The overall idea of how RPZ works is that you can create policies for how to handle specific queries (or responses) and choose which of a number of possible actions to take. Examples of possible actions include redirecting the client to an internal security page and storing those policies in special authoritative zones on your DNS servers. You can also share RPZ zones by transferring them from DNS server to DNS server.
You can get RPZ data from a threat intelligence provider (where they are the primary for the zone and you are the secondary); or you can make these zones yourself (where you are the primary of the Zone). RPZs make policy data available in DNS zones. The policy data is then transferred between servers using conventional DNS protocols.
Want more information on Response Policy Zones (RPZ)? Find it here.
3.4 Query Logging and Reporting
Query logging is one of the major ways for a DNS system to produce raw data on what questions are asked, while reporting is the organization and transformation of that raw data into humanly readable formats.
Query and Response Logging
As a DNS server sends queries (“What is the AAAA record of www.example.com?”) to other DNS servers, it can keep a copy of these queries. Retaining queries in this manner can be useful when troubleshooting DNS-related issues. In addition, the information can be processed later to generate reports with information such as “What was the most queried domain name in the last hour?” System log or syslog is typically the mechanism to record this query information, a process known as query logging. While query and response logging provide additional information that may be useful for troubleshooting and analytics, both processes add significantly more I/O (Input/Output) load to the DNS servers and are typically disabled by default in operational environments.
Analytics and Reporting
After enabling logging, that information doesn’t provide much value just sitting on the DNS server itself in syslog. For administrators to take advantage of the information, it must be collected and analyzed centrally, to correlate with logging information from other DNS servers. Syslog is one of the most popular ways to record and transport this information to a central location.
Good reporting is essential to system monitoring and maintenance. For example, having two (2) reports side-by-side – one showing the number of outbound DNS queries, one showing the CPU usage on the DNS server – could be very useful in helping a system administrator to determine whether or not the DNS server has sufficient computing resources allocated. Similarly, administrators can generate historical usage reports, such as “Show DNS daily average in the last 12 months,” and spot whether or not there has been a steady increase in the volume of traffic.
Learn more about query logging and reporting.
3.5 DNS Threat Intelligence
The term threat intelligence is a generic industry term that refers to any compiled data, usually in the form of a list or “feed,” that identifies active cybersecurity threats.
Cyber Threat Intelligence
Cyber threat intelligence is information on potential threats against your organization, such as attack methods to take down the network infrastructure, or ransomware to extort money. Security researchers around the world gather and analyze raw data about emerging or existing threats, and compile them into threat intelligence lists or feeds. The feeds are published either directly by security researchers, or more often, published through a security vendor.
Threat intelligence can be built from both external and internal sources. While external threat intelligence provides generic umbrella protection, attacks targeted specifically at your organization or group can only come from good internal threat intelligence. This is information gathered based on the behavior of your users and their network activities, and typically requires a dedicated security team and/or appliance to monitor, analyze, and produce the data.
DNS Threat Intelligence
DNS threat intelligence is specifically tailored for DNS services, meaning it contains a list of malicious domain names. Because the DNS already has publishing (zones) and updating mechanisms (zone transfer) in place, the distribution of DNS threat intelligence can be done natively through the use of Response Policy Zones (RPZ). Whenever new feed data is available, it gets sent via incremental zone transfer to the subscribers. External threat intelligence for DNS is also readily available.
Today’s more advanced DNS security products, such as Infoblox Threat Insight, inspect the traffic on-the-wire, as the queries and responses are passing through the DNS servers, analyzing them in real-time. This approach builds internal threat intelligence much faster, and is more suited for the fast-paced world of security. When dealing with large amounts of queries, the detection engine can tap into the greater computing power of the cloud, alleviating the DNS servers of any performance degradation, while catching the attacker red-handed as the crime is still in progress.
4. DNS Client Security
4.1 DNS over TLS (DoT)
The Privacy Problem
It is no secret that the original DNS design did not take security into account. While DNSSEC addresses many of the security shortcomings of the traditional DNS design, especially in server-to-server communication, it falls short in adequately addressing the “last mile” problem, that is the communication between DNS client (such as a mobile phone) and its nearest DNS server (such as the corporate or ISP DNS server).
To fill this big gap that is the “last mile,” many competing technologies have emerged over the years, such as DNSCurve and DNSCrypt. While these technologies try to bring privacy between DNS client and server, they have one thing in common: they are proprietary and non-standardized. The standards body IETF (Internet Engineering Task Force) recognizes the need for DNS privacy, and released two new standards in 2016 that address these needs.
DoT basics
To understand DoT, we first need to understand TLS, Transport Layer Security, formerly know as SSL (Secure Socket Layer). SSL started in the 1990’s and lived to see version 3.0, before major deficiencies in the protocol itself took it down. The enhanced replacement was TLS, and the version number started back up at 1.0 again. While the latest version of TLS is 1.3 as of this writing, DoT was largely based on version TLS 1.2.
In a standard TLS communication, the client reaches out to the server, obtains the server’s certificate (usually a X.509 cert), and runs through the standard certificate authority validation process. After the client decides to trust the server, they negotiate an encryption key, and are ready to start encrypting data. This is known as a TLS handshake.
RFC 7858 specifies that DoT uses TCP port 853 for secure DNS communication. Just like any TLS-based communication, a DoT DNS client first reaches out to the DoT-enabled DNS server on port 853 and performs a TLS handshake. The DoT client receives the server’s certificate, somehow validates it (more on this later), then generates a symmetrical encryption key that they both agree on (such as AES) for the actual data encryption. In short, DoT uses the same technology that your web server certificate uses, it just runs over a different TCP port.
DoT has two operation modes, a strict mode, and an opportunistic mode. In the strict mode the DoT client has a list of trusted DoT server certificates, and only communicates with trusted DNS servers. In the opportunistic mode, the DoT client attempts to talk to any DNS server over TCP port 853, and when it fails to establish a secure communication channel, it falls back to using port 53 for traditional insecure DNS.
Like DoH, with DoT we can protect the communication for each hop between server-client or server-server, however, it does not provide the authentication and integrity checking that DNSSEC offers. Different from DoH, DoT can be deployed to secure server-to-server communication, making it a technology that protects beyond the “last mile.” These technologies are not mutually exclusive, they can be deployed to complement each other.
4.2 DNS over HTTPS (DoH)
The Privacy Problem
While DNSSEC addresses many of the security shortcomings of the traditional DNS design, especially in server-to-server communication, it falls short in adequately addressing the “last mile” problem.
Truth be told, there are two major reasons why DNSSEC is the wrong tool for this job:
- DNSSEC does not encrypt traffic: DNSSEC uses public key cryptography to provide authentication and data integrity, so we know precisely who sent the data, and whether or not that data changed during transmission. However, it does not provide any privacy, meaning someone eavesdropping on the wire can still see all the DNS message in the clear; it is just extremely difficult for them to alter the data.
- DNSSEC validation is resource intensive: DNSSEC validation requires more computing power and network queries to fully validate an answer. While it is possible to have the client perform all of these queries itself, we do not do it for the same reason why we have a local DNS server: so nearby clients can share the resources and cache of the server, and spare themselves the busy work.
To fill the last mile gap, many technologies have emerged over the years, such as DNSCurve and DNSCrypt. These technologies have one thing in common: they are proprietary and non-standardized. The standards body IETF (Internet Engineering Task Force) recognizes the need for DNS privacy, and released two new standards in 2016 that address these needs. In this article, we will be discussing one of the two new standards, DNS over HTTPS, or DoH as it is commonly referred to. It also has drafts being worked on for both Confidential DNS and IPSECA.
DoH Basics
To understand DoH, we first need to understand HTTPS. Many people may know the S stands for SSL (Secure Socket Layer), and the modern version of HTTPS is based on TLS, Transport Layer Security, the successor to SSL.
In a standard HTTPS communication, a client (usually a web browser) reaches out to the web server, obtains the server’s certificate (usually a X.509 cert), and runs through the standard certificate authority validation process to decide whether or not it trusts this server, i.e. is it signed by a certificate authority the client trusts, etc. After the client decides to trust the server, they negotiate an encryption key, and are ready to start encrypting data. This is known as a TLS handshake.
RFC 8484 describes DoH at a high level. A DoH client reaches out to a DNS server that supports DOH over standard TCP port 443. The DoH client receives the server’s certificate, somehow validates it (more on this later), then generates a symmetrical encryption key that they both agree on (such as AES) for the actual data encryption. In short, DoH behaves exactly like a web browser, with the exception that it encodes DNS data within HTTPS sessions in the form of GET and POST messages.
Similar to DoT, DoH protects the per-hop communication between server and client; but different from DoT, it is not intended to be used to secure server-to-server communication. This means DoH is truly a technology meant to secure the “last mile.” Similar to DoT, DoH does not provide the authentication and integrity checking that DNSSEC offers.
5. DNS Security Best Practices
DNS is now critical to the operation of nearly every non-trivial networked application. DNS has also become dauntingly complex, both in theory and in its implementations. And unfortunately, hackers increasingly target DNS infrastructure.
Use Dedicated DNS Appliances
DNS Appliances, like other network appliances, are purpose-built and as such are both hardware and software configured for ease of management, security, and performance. Common OS servers cannot match the tuning that these appliances offer. DNS appliances benefit from all the same advantages that other network appliances do, including but not limited to unnecessary ports, limited driver requirements, to limiting other network chatter on interfaces, to maximizing RAM availability – these appliances win in every area. Additional information can be found here: the benefits of using dedicated DNS appliances.
Keep DNS Server Software Up-to-Date
With DNS becoming an ever-increasing target of attacks both against DNS itself and by using DNS for everything from command and control to data exfiltration, it has never been more imperative to be on the latest and greatest code for your solution.
Have an Onsite DNS Backup
Onsite backup provides you with the ability to get your DNS operations back up and running as quickly as possible. Again, a central solution that allows you to spin up an entire DNS architecture all at once is a huge benefit.
Avoid Single Points of Failure
Given that web, mail, chat, and even sometimes voice can depend on DNS, it must be considered a critical network component. Add to that the increasing use of DNS as part of an organization’s comprehensive network security architecture and it becomes even more critical. While DNS inherently provides protocol redundancy, in today’s world that is not always enough. The time to switch between servers varies on many factors, including client OS and the server software running on intermediate servers. While these failovers can be tolerable for simple usage, it cannot compete with providing hardware redundancy to the protocol redundancy, allowing failures to be faster and invisible to clients as the IP of the server doesn’t change.
Turn Off Recursion on Authoritative servers
Inside your organization:
Allowing your servers that hold your authoritative servers (which hold your data) to talk to any DNS server in the world is just not a best practice. Adding a dedicated recursive caching layer to your design means that your authoritative servers only connect to dedicated caching recursive servers that do not contain your organization’s data. It also can speed resolution as a centralized cache can be more robust and actually result in less DNS traffic being sent.
On the Public facing side:
Allowing recursion on your external-facing DNS servers has long been a strict no-no. For the typical organization, ensuring that you have recursion disabled on any public-facing DNS server is a strong best practice. It makes it easy for attackers to find weaknesses in caching functions that could, in turn, diminish or stop the ability of the server to answer your authoritative data. Attacks that cause server restarts or buffer overflows are just two examples of the risks you add when mixing authoritative and recursive functions on one server.

