DNS Security Overview
What Is DNS Security?
DNS is becoming a more common target of network attacks. As one of the oldest and most relied-on protocols of the modern Internet, DNS is utilized by almost all other services and protocols, making DNS an appealing target to attackers. Because it is one of the most relied-on protocols, stopping attacks can’t be as simple as adding a firewall rule. It is good to know how these attacks work before discussing solutions to stop them.
In general, DNS attacks are like wine in that they come in two main types: “reds” and “whites”. In DNS attacks, the two primary attack types are Authoritative attacks and Caching Recursive attacks. Authoritative attacks include DDoS attacks, Amplification attacks, or Reflection attacks, to name a few. Caching Recursive attacks, such as Cache Poisoning attacks, or DNS Hijacking attacks. Just like wine, there are also a few outliers, such as DNS Tunneling attacks. However, most DNS attacks are either Authoritative or Caching Recursive.
The process of securing DNS is complicated because, unlike most other protocols, the principal purpose of DNS is to both publish information as well as allow clients to access that information. So, the methods we use to defend DNS, often have to stay away from the classic, simple blocking techniques.
We often get asked, “What is DNS Security and how does it work?”. In this section of the site, we try to answer just that. The tools at our disposal to protect DNS include but are not limited to signature recognition, Resource Rate Limiting(RRL) and Response Policy Zones(RPZ). First, let’s briefly review the history of DNS and what it includes.

DNS History
DNS stands for Domain Name System and is an Internet protocol that converts human-readable names to IP addresses, changes IP addresses back to names, and provides easy-to-remember names for many Internet-based services, such as e-mail.
At the dawning of the Internet, or as it was known back then, the ARPANET (Advanced Research Projects Agency Network), very few people and machines were online. Each computer using the Internet had an IP address, but since there were so few IP addresses, memorizing them was not a big deal.
As the number of machines quickly grew, people thought it would be a good idea to use more human-friendly names. Instead of remembering a computer’s IP address, such as 128.171.32.45, ARPANET users could enter names such as GOPHER-HAWAII. A single text file named HOSTS.TXT served as a name-to-address map. The Stanford Research Institute (then a part of ARPANET) manually maintained the file, also known as the hosts file, in a single place, and distributed it to ARPANET users.
Back then, if you wanted to translate a name to an IP address, you needed to download the latest copy of the hosts file. Likewise, if you wanted to be known by the other parts of ARPANET by name, you needed to contact the maintainer of the hosts file and add yourself to the list.
This centralized system quickly proved unscalable. Computer scientist and Internet pioneer Paul Mockapetris began work writing a standards document to define a replacement for host files. He took his proposed standard to the Internet Engineering Task Force (IETF), which still today produces standards documents that define how Internet protocols should operate and interoperate.
In 1983, Mockapetris published the first standards document in the IETF related to DNS. This document would become the basis for the DNS. His proposal called for a decentralized, distributed structure of name servers. More than 30 years later, this same system is still very much in use, making Paul Mockapetris the official Father of DNS. Figure 1-1 shows a timeline that summarizes the evolution of DNS through 1987.

Figure 1-1: DNS is a decentralized, distributed structure of name servers that has enabled the Internet to scale.
DNS Structure
DNS distributes responsibility for an ever-growing list of network device names. It does this by creating a hierarchy of responsibility. This hierarchy is often represented by an upside-down tree, such as Figure 1-2, where the root servers are at the top, and the leaves (which represent all the end host nodes on the Internet) are at the bottom. The entire tree represents the namespace of DNS. Each server that is responsible for part of the namespace is called a “name server.” Some name servers send packets along until they reach an answer.
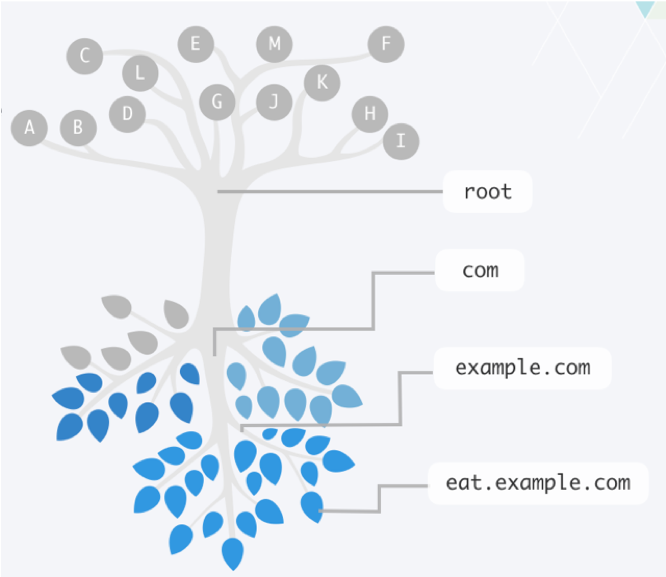
Figure 1-2: Like the branches of a tree, each domain name can have multiple subdomains.
The root name servers direct DNS queries to name servers for each of the top-level domains, which are the main branches just below it (for example, .com, .net. jp, and .info,). Root name servers are authoritative name servers for DNS’s root zone, which is sometimes written as a single dot (“.”) and contain just the information needed to delegate questions to the name servers below it in the top-level domains. Being authoritative for a zone means being responsible for that domain, except the parts delegated to different authoritative name servers.
Name resolution is the process of following these delegations of responsibility until reaching the name server that has the answer, i.e., the authoritative server for that zone. Root name servers are a critical part of the Internet infrastructure because they represent the first step in name resolution. Thus every name server in the world needs to know about them in order to walk down the tree to the end host it is looking for. The list of root name servers, including their names and addresses, resides on virtually every DNS server in a file known as the root hints file.
This feature allows a company like “Example,” shown in Figure 1-2, to register the domain name “example.com” and manage just the subdomain names within that domain. The rest of the world doesn’t need to know where Example’s name servers are. When an Internet user wants to visit example.com, the user’s local DNS server can ask the root name servers, which sends it to .com name servers, which will, in turn, send it to the example.com name servers. The example.com name servers have answers for any subdomain names within example.com.
This process is explained in more detail in the section on Query path, Recursion, and Iteration.
Authority and Zones
A DNS zone is a domain that a party is responsible for maintaining, minus any subdomains the party delegated control of to another party. The responsible party uses that zone to maintain the resource records for that domain. Resource records map information to common names. The server where the party edits the resource records is typically called the primary name server. Because a single server isn’t enough for a robust solution, additional name servers can also be authoritative for a zone by getting a copy of the zone data from the primary server through a process called a zone transfer. These additional servers are called secondary name servers.
The data on the primary server is the only version that a person should ever edit. The secondary server receives information only as a copy of the data on the primary server. Nobody should ever edit the data directly on the secondary server.
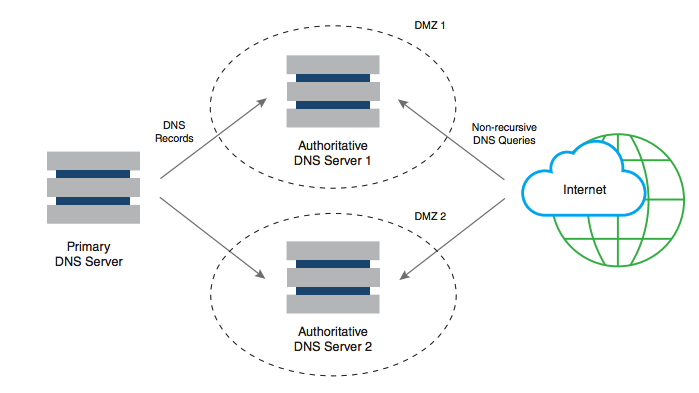
Figure 1-3: Primary and secondary name servers store the resource records for a domain.
Resource Records and common uses
Resource records identify the information or services associated with a given domain name.
All resource records use the same format, which we discuss in the following list:
- Name: A domain name in which this resource record pertains.
- TTL: A 32-bit integer that specifies the time interval that the resource record may be cached before it should be discarded.
- Class: Two octets which specify the class of the data in the RDATA field. The most common type is IN for Internet.
- Type: This field specifies the meaning of the data in the RDATA field.
- RDLENGTH: A 16-bit integer that specifies the length in octets of the RDATA text, for instance, how large is the payload.
- RDATA: A variable-length string that describes the resource. The format varies according to the TYPE and CLASS of the resource record.
Although all resource records share a common overall structure, they may contain different types of information in their RDATA field, such as network- or service-specific information.
To understand resource records, you need to understand the NAME field a bit more. The NAME field contains a domain name associating this name to various information. If the information is about the domain itself that is enough, but when the information related to an end host then a fully qualified domain name or FQDN is used. The FQDN has two parts: the hostname, and the domain name.
For example, consider FQDN www.example.com. In this FQDN, www is the hostname, and example.com is the domain name. Each word that is separated by the dot character is also known as a label, so “www” is a label, “example” is a label, and “com” is a label.
There can be more than one resource record associated with an FQDN. All the resource records associated with an FQDN that have the same values in the NAME and TYPE fields, regardless of their RDATA value, are considered a Resource Record Set (RRSET).
Common Uses
Each of the following sections discusses a type of record and lists the most important fields in the record with example data. However, we have omitted two important fields from each section:
- We omitted the CLASS field because, for all common record types, the value is IN for Internet.
- We omitted the RDLENTH field because it is just a reference to the length of the data. It could be any value.
A Record
A records are the most common record used in DNS. These records match easily remembered hostnames to the IP addresses of the resource. Figure 1-4 is a sample A record.

Figure 1-4: The RDATA field in an A record contains the IP address of the resource.
AAAA Record
AAAA records (or quad-A, as they are often called) are used to map hostnames to their IPv6 addresses. Figure 1-5 is a sample quad-A record.

Figure 1-5: The RDATA field in a quad-A record contains the IPv6 of the resource.
SOA Record
The SOA record, which stands for Start of Authority records, provides the querier, including secondary servers and recursive servers, information about the zone itself including the primary name server (pname), the responsible party (rname), and timers for how the zone and its records should be handled.
The timers that appear in the RDATA field are:
- Refresh: How often a secondary server should contact the primary server for updates
- Retry: How soon a secondary server should try contacting the primary server if an attempt fails
- Expire: How long a secondary server can hold the zone data when it cannot reach the primary server
- Minimum: How long recursive name servers can cache a negative answer, such as NXDOMAIN, also known as NCACHE for negative cache
Figures 1-6 and 1-7 show a sample SOA record.

Figure 1-6: An SOA lookup returns a lot of information in the RDATA field compared to other resource records, including the pname (identifies the primary name server) and rname (identifies the email address of the responsible party for the zone)
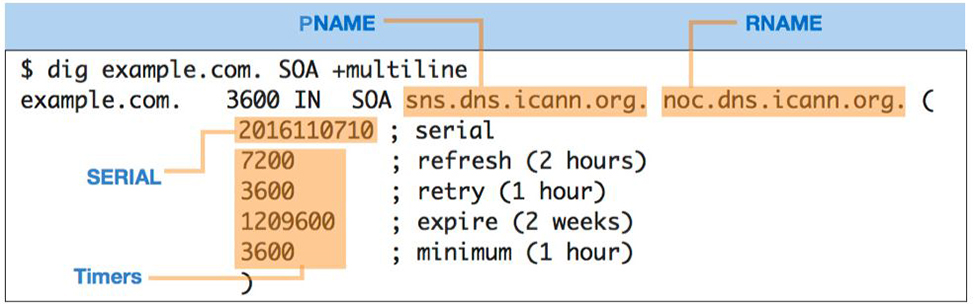
Figure 1-7: The RDATA field in an SOA record provides detailed information about the zone itself, including the primary name server, the responsible party, and timers for how the zone and its records should be handled.
Other Record Types
CNAME
CNAME records map additional names back to a hostname, like an alias. A typical use of this kind of record is to map service names to a server name.
PTR
PTR records map an IP address back to the hostnames that exist for the IP Address. PTR records are mostly used by applications and systems to determine the name associated with the IP address.
NS
NS records publish the name of the name servers for a domain. They are used by other DNS servers to find the authoritative name servers of a domain.
MX
MX records allow DNS clients to find mail servers for the domain.
TXT
TXT records allow an FQDN to be associated with a text string. TXT records initially provided information about the host associated with that name. Today it more often used in security by helping to verify the host by providing hashes and other information.
SRV
SRV records define the resources required to support specific Internet services (e.g., SIP, XMPP). SRV records include hostname and port numbers, as well as target host priority and host relative weighting.
Query Path, Recursion, and Iteration
Query path and Recursion
A query path is the set of queries starting from the initial question from the client and finishing with the answer the client receives. A query path can be as simple as a client asking a server and receiving an answer directly. However, a query path can also be complex and include multiple servers working together to track down the answer. Understanding the query path of a given question allows you to troubleshoot issues and identify where you need to focus your DNS security.
It’s important to understand what we mean when we say a client asks a question. When a DNS client asks simple questions like “What is the IPv4 address of www.google.com?” a stub resolver is the piece of software code that sends the DNS question. For the scope of this book, we can assume that a “client” is an application or a machine that has a stub resolver running on it. Therefore, a web browser is a client, and a laptop or mobile phone can also be a client.
When a client asks a question, it is unable to follow referrals given by other name servers to track down the answer on its own. It has to rely on a full-fledged DNS server, which may call on other name servers, to chase down the answer. This name server acting on behalf of the client is called recursion.
Figure 1-8 illustrates several name servers involved in answering a simple question.
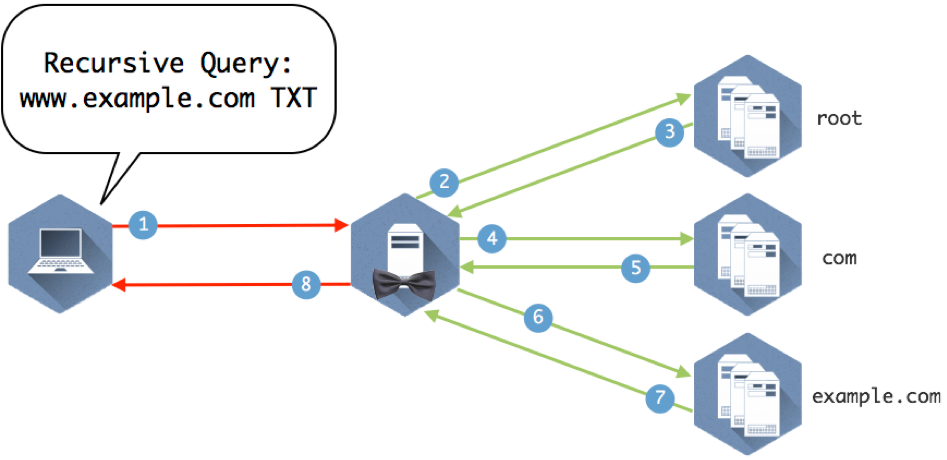
Figure 1-8: Eight queries and answers make up the query path required to get this client the answer to “What is the IP address of www.example.com”?
Now we can take a look at the different parts of the query path in Figure 1-8 and break down how the servers use recursion and iteration to move down the DNS tree and find the answer the client is looking for.
Recursion is the process repeatedly asking the question to name servers and following referrals until finding the name server with the answer. The recursive query says, “I would like to know the answer to this question. Moreover, if you don’t know the answer, please ask others until you’ve found the answer.” It is this behavior of asking on behalf of the end client that is considered recursion.
All clients ask recursive queries by default because clients are usually not capable of “walking the tree” to chase down the answers on their own. A name server providing recursion accepts recursive queries and fulfills them by executing iterative queries in the background to track down answers. As a result of processing recursive queries, recursive name servers build up a rich cache of answers over time. Thus they are also known as caching name servers.
Iteration
An iterative name query is typically sent by DNS servers to other DNS servers, in pursuit of finding the answer. A critical difference between iteration and recursion is that iterative queries must have the ability to follow referrals, i.e., track down the answer.
Figure 1-9 provides the details to the query path to illustrate how it all comes together.
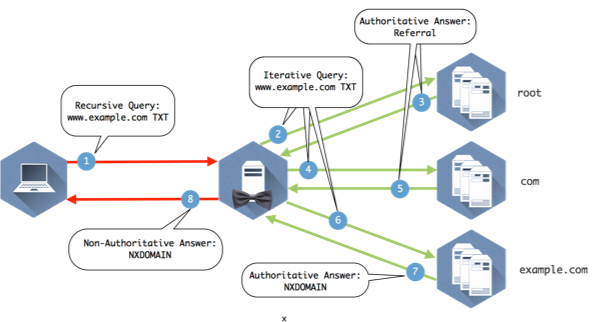
Figure 1-9: Explanation below
- The client queries the recursive name server that it is configured to use.
- The recursive server checks its internal cache. If it doesn’t find the answer to the question, it checks its root hints file and sends the query to one of the 13 root name servers listed in the file.
- The root name server does not contain specific records that answer the question, but it does know where the com name servers. It sends a referral in the form of the NS RRSET for the com name servers and the A records for those name servers. These matching A records are called glue records.
- The recursive server caches the responses from the root name server and queries one of the com servers it was given for www.example.com
- The com name servers do not contain www.example.com, but someone has registered example.com and provided com with the information for their name servers. The com name server sends a referral of the NS and A records for example.com
- The recursive server caches the records from com and queries one of the example.com name servers provided in the referral.
- The example.com name server returns the answer from the authoritative zone example.com
- The recursive name server caches the answer returned from the example.com name servers and sends the response to the client.
